
MOMO AI is a fictitious EdTech company I created to simulate a real-world case for designing a Google Cloud Landing Zone.
They're doing really interesting stuff in AI-powered learning — and their user base has grown like crazy, passing a million active users. Not bad for a startup.
What is MOMO AI ?

Like many fast-scaling startups, Momo AI’s cloud environment grew fast — but not always in the cleanest way. A handful of GCP projects were created manually, IAM roles were added ad hoc, and there was no clear structure to speak of. It worked for getting things moving, but it wasn’t going to support the kind of growth they were heading into.
With a clear goal to move 100% to Google Cloud by 2027, they brought me in as an external GCP architect to help design something solid: their Landing Zone.
To really understand their needs and context, I spent time on-site with the Momo team at their HQ in Tunisia. We ran a series of working sessions — just me and four of their core tech leads — sitting around a table, diving into architecture, sketching on whiteboards, and asking the real questions that shape a scalable foundation.
Momo AI GCP Design Workshops — Real Conversations, Real Decisions
We've broken down the Landing Zone design process into focused workshops. Each session is designed to guide the team through foundational decisions — from identity to infrastructure — with the goal of building a scalable, secure, and well-governed Google Cloud environment.
Workshop 1: Identity & Access + Resource Hierarchy
What to cover:
- Identity Strategy: Choose a master identity provider (Cloud Identity or federated AD/SSO), group design, and SSO integration.
- IAM Best Practices: Group-based access, least privilege, and service account governance.
- Org Hierarchy Design: Define folders (e.g., shared vs. teams), align them to billing, teams, or environments.
- Naming & Tagging Conventions: Plan naming standards, labels, and tags to enforce structure and traceability.
Workshop 2: Networking Foundations
What to cover:
- VPC Topology: Decide between flat, hierarchical, or hub-and-spoke models.
- Hybrid Connectivity: Review options like HA VPN and Interconnect.
- Shared VPC Strategy: Define host and service projects for environment separation.
- DNS & IP Planning: Design private/internal DNS zones and IP ranges to prevent overlap and simplify routing.
Workshop 3: Security Architecture
What to cover:
- Org Policy Constraints: Enforce guardrails (e.g., no public IPs, allowed regions).
- Encryption Strategy: Decide when and where to use CMEK.
- Network Security: VPC firewall strategy, private access, and service controls.
- Identity Hardening: Just-in-Time access, audit trails, and privileged access workflows.
Workshop 4: Logging & Monitoring
What to cover:
- Logging Design: Choose central vs. per-project aggregation, sinks, and filters.
- Monitoring Scope: Define metrics scope strategy (single project or aggregated).
- Dashboards & Alerting: Setup custom dashboards (Looker Studio, Cloud Monitoring) and alert policies tied to SLOs/SLIs.
- Retention & Cost: Decide what logs/metrics to store, for how long, and where.
Workshop 5: Billing & FinOps
What to cover:
- Budgeting Strategy: Per-project and per-team budgets, with real-time alerts.
- Cost Attribution: Enforce labels for cost centers, environments, and teams.
- Reporting Pipeline: Export billing data to BigQuery, visualize with dashboards.
- Sprawl Control: Prevent zombie resources with policies and automation.
Workshop 6: Infrastructure as Code (IaC)
What to cover:
- IaC Standards: Pick Terraform, with module reusability in mind.
- CI/CD Integration: Use GitOps for infra — review, plan, validate, deploy.
- Environment Bootstrapping: Define how new environments (dev, staging, prod) get created consistently.
- Starter Modules: Evaluate Cloud Foundation Toolkit (CFT) or build custom baseline modules.
Participants:
| Name | Role | Note |
|---|---|---|
| Yasmine | Co-founder and CTO | Vision-driven, with a sharp eye on scaling responsibly. |
| Walid | Infra Lead | Hands-on with all their cloud infra, knows what’s broken. |
| Rami | Data Engineering Lead | Quiet but deadly with pipelines and platform strategy. |
| Nour | Security & Compliance Lead | Sticks to the rules. And rightly so. |
| Mohamed (me) | External GCP Architect | Mapping all this chaos into one sane Landing Zone 🙂 |
Workshop 1 : Identity & Access + Resource Hierarchy - Part 1
Me : "Alright team, let's kick off with identity. This is foundational for everything we do in Google Cloud. At its core, Google Cloud uses two main components for managing who can do what: Cloud Identity handles who a user is – that's the authentication part, proving you are who you say you are. Then, IAM – Identity and Access Management – decides what you’re allowed to do once you’re in – that's the authorization."
⚠️ Before you can get started with Google Cloud for your organization, you’ll need to set up Cloud Identity — this is the first step in the onboarding process.
- Set up Cloud Identity
This is the first step before onboarding your organization to Google Cloud. - Add your organization’s domain
Typically, this will be your company’s main domain (e.g., momo.ai). - Verify domain ownership
You’ll receive a TXT record to add to your domain’s DNS settings. This confirms the domain is yours. - Google Cloud organization is created
Once verified, Google will automatically create your Cloud organization, named after your domain. - Begin using Google Cloud
You're now ready to explore and use Google Cloud services with your organization setup.
Nour : how Cloud Identity connects with Google Cloud ?
Mohamed: "Cloud Identity handles who a user is (authentication) and manages your users and groups, acting as your central identity provider. IAM then uses those Cloud Identity groups to define what they're allowed to do (authorization) on your Google Cloud resources. They work hand-in-hand: Cloud Identity verifies the identity, and IAM grants permissions based on that identity."
⚠️ When working with Google Cloud we have two consoles for administration :
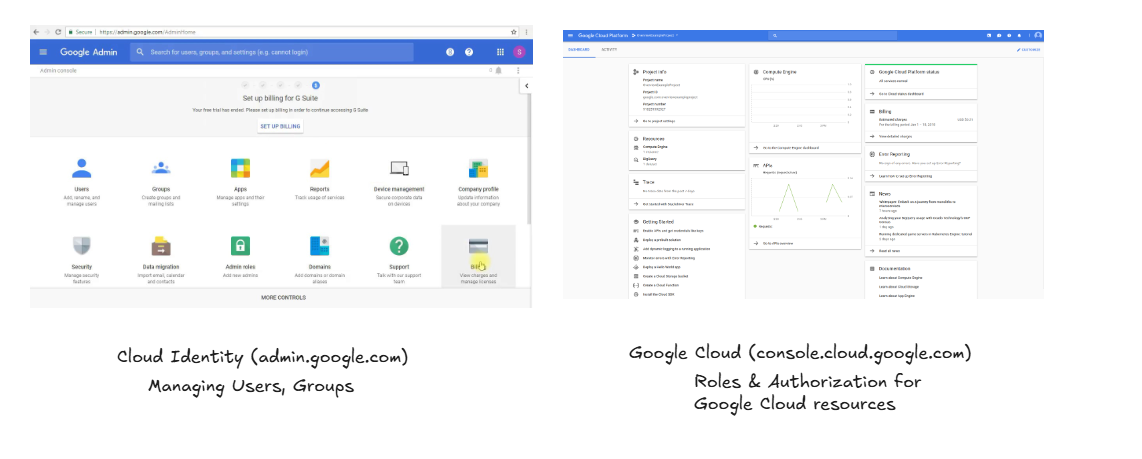
Me : "Great Guys , One of the very first things we need to figure out for Momo is: which identity system will be our 'source of truth'? In other words, which one will be our main Identity Provider (IdP)? This decision is crucial because it shapes how all your users log in, how we manage groups and roles, and how everything integrates across all your systems."
Nour : We Have an On Prem AD which we use to manage our users , it ist fine ?
Me : yes it is great !
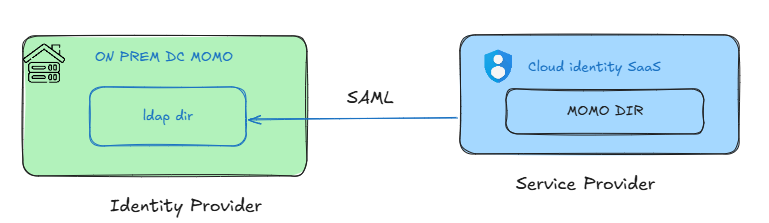
We kicked off with identity. They’re using Active Directory on-prem, which works — but they needed it integrated cleanly into GCP and federated with SAML.
So here’s what we landed on:
- One Cloud Identity domain needed : momo.ai
- AD On PREM is default Idp and source of truth.
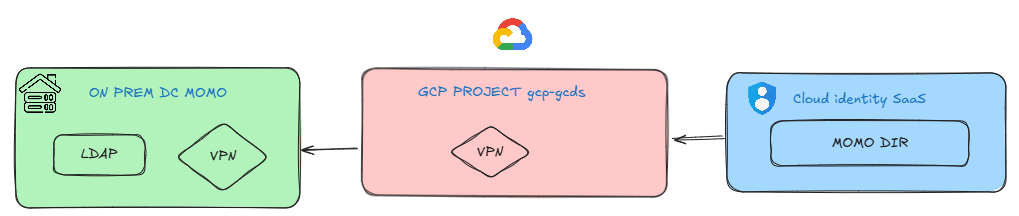
Nour : But Mohamed , how will user’s and groups be synchronised?
Me : Great Nour ! we Sync AD to Cloud Identity using a GCP service called Google Cloud Directory Sync.

Me : this is how we set up federation with SAML, so users log in with their momo accounts :)
Me : "Alright, let's talk about how we actually apply those permissions we just discussed. While IAM lets us grant roles to individual users, that quickly becomes unmanageable and a security nightmare. Our best practice, and what Google Cloud strongly recommends, is to use groups."
Me : "We'll create highly scoped groups for different functions and teams. Think of it this way: we'll have some broader, organization-wide groups, likegcp-org-adminsorgcp-security-admins, for those who need overarching access. But then, we'll also create much more focused groups at the project level, likegcp-project-ml-prod-engineersorgcp-project-data-dev-engineers."
Me : "The beauty of this is that these project-level groups will typically get set up automatically as part of our infrastructure-as-code flow whenever we onboard a new team or workload. It's built right into the process."
Nour: “Please, no one-off permissions for users. Everything has to go through groups.”
Me : "Exactly, Nour! That's the golden rule. No individual user should ever have direct, one-off permissions. Everything flows through these well-defined groups. This approach simplifies management, enhances auditability, and significantly reduces the risk of accidental over-privileging."
So here’s what we landed on:
Create a set of initial groups which will be used to manage access to Cloud resources :
| Group Name | Role / Purpose |
|---|---|
gcp-organization-admins |
Full org-level control (OrgAdmin, PolicyAdmin) |
gcp-billing-admins |
Manage billing accounts and cost configurations |
gcp-billing-viewer |
Able to view project spend; useful for finance teams |
gcp-security-admins |
Manage org policies, SCC, IAM, guardrails |
gcp-devops |
CI/CD pipelines, Terraform, and deployment operations |
gcp-network-admins |
Configure VPCs, subnets, firewalls, DNS, and peering |
And other scoped groups using the naming convention : gcp-{env}-{app-role}
For example :
gcp-prod-data-admin
Dear Reader , If you use Cloud identity this way, how did it go for you?
Workshop 1 : Identity & Access + Resource Hierarchy - Part 2
Me : "Alright team, we've talked about who gets in the door with Cloud Identity and IAM, and how we manage permissions with groups. Now, let's zoom out a bit and talk about the overall structure of your Google Cloud environment. This is what we call the resource hierarchy, and it's absolutely critical for managing your cloud effectively as you scale."
Me : "To break down the components: The root node of this hierarchy is called the organization. For Momo, this will typically align to your momo.ai domain name. Below that, a resource is any service or object you consume in Google Cloud – a VM, a storage bucket, a load balancer, anything. Every single resource belongs to one and only one project. The project is the most basic unit of organization for your GCP resources, and as I mentioned, all billing is initially captured at this level."Me : "And then, a folder is an optional layer that allows us to group projects, or even other nested folders, providing that logical segmentation we need for teams and shared services."
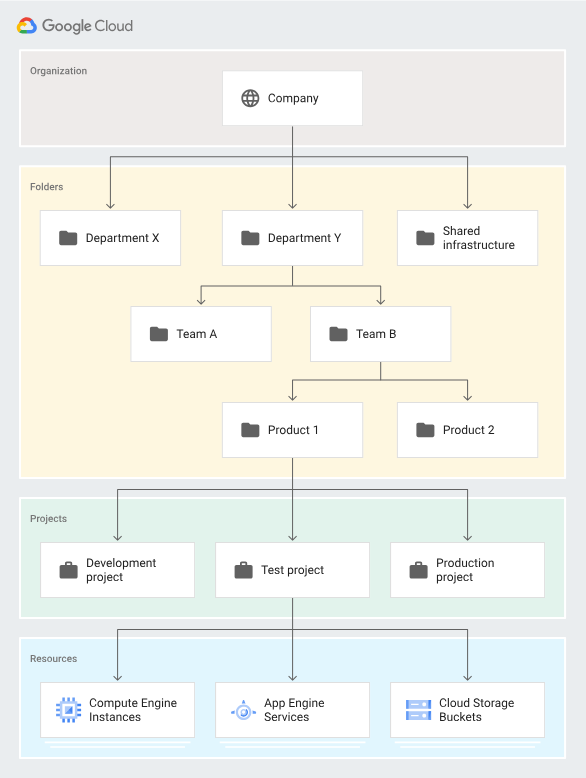
So here’s the deal. Momo’s growing fast, and like most startups, their cloud setup was kind of a mess — random projects, no clear folder structure, and definitely no IAM sanity. We needed something that could scale but also didn’t make developers miserable.
After a couple of long calls and a few whiteboard diagrams, we decided to go with a split model.
Core (Shared) Stuff
These are the things you don’t want every team messing with — shared networks, interconnects, DNS, security baselines, that kind of thing. We put all of this under a top-level folder called shared, and it’s managed by a small infra team who knows what they’re doing.
The idea is: if you’re not part of platform or infra, you don’t touch this.
Team & App Resources
Then we created folders like teams/data, teams/ml, and so on. These are for the actual app teams — they deploy stuff, break things, fix them, and move fast. But they do it in their own playgrounds. They have budgets, logging, alerts — all scoped to their folders.
Everyone’s happy.
MOMO.ai/
├── shared/
│ ├── networking/
│ │ ├── vpc-host-prod
│ │ └── vpc-host-nonprod
│ ├── observability/
│ │ ├── monitoring-prod
│ │ └── monitoring-nonprod
│ ├── logging/
│ │ └── central-log-project
│ └── billing/
│ └── cost-control
├── data-platform/
│ ├── Prod/
│ │ └── momo-data-prod
│ ├── Nonprod/
│ │ └── momo-data-nonprod
│ └── Dev/
│ └── momo-data-dev
├── teams/
│ ├── ml-ai/
│ │ ├── Prod/
│ │ │ └── momo-ml-prod
│ │ ├── Nonprod/
│ │ │ └── momo-ml-nonprod
│ │ └── Dev/
│ │ └── momo-ml-dev
│ ├── frontend/
│ │ ├── Prod/
│ │ │ └── momo-ui-prod
│ │ ├── Nonprod/
│ │ │ └── momo-ui-nonprod
│ │ └── Dev/
│ │ └── momo-ui-dev
│ └── internal-tools/
│ ├── Prod/
│ │ └── momo-tools-prod
│ ├── Nonprod/
│ │ └── momo-tools-nonprod
│ └── Dev/
│ └── momo-tools-dev
├── sandbox/
│ └── dev-playground
Why this Hierarchy Works Well:
Separation of Concerns
shared/: all infra owned centrally (networking, observability, billing)teams/: per-product or per-team resourcesdata-platform/: if it’s a horizontal concern across teams, it’s good to break it outsandbox/: isolated, non-critical space — often forgotten but super valuable
Need to take decision on resource hierarchy ? , check this doc :
Workshop 2 : Networking

Network design came up in our second workshop — and like always, the room got a little more animated. Everyone has opinions when it comes to routing and VPNs.
So I kicked things off:
Me:
"Alright folks, let’s get into your current GCP connectivity. Walid, what do you have in place today?”
Walid (Infra lead):
“Nothing too fancy. Just an HA VPN from our DC in Tunis to GCP. One tunnel — wired into dev for now.”
So far, so good. I’ve seen plenty of companies at this stage.
Me:
“Cool. Do you plan to switch to Interconnect ?”
Yasmine (CTO):
“Not right away. The HA VPN’s working, and Interconnect is pricey”
For example a typical HA VPN design looks like this:
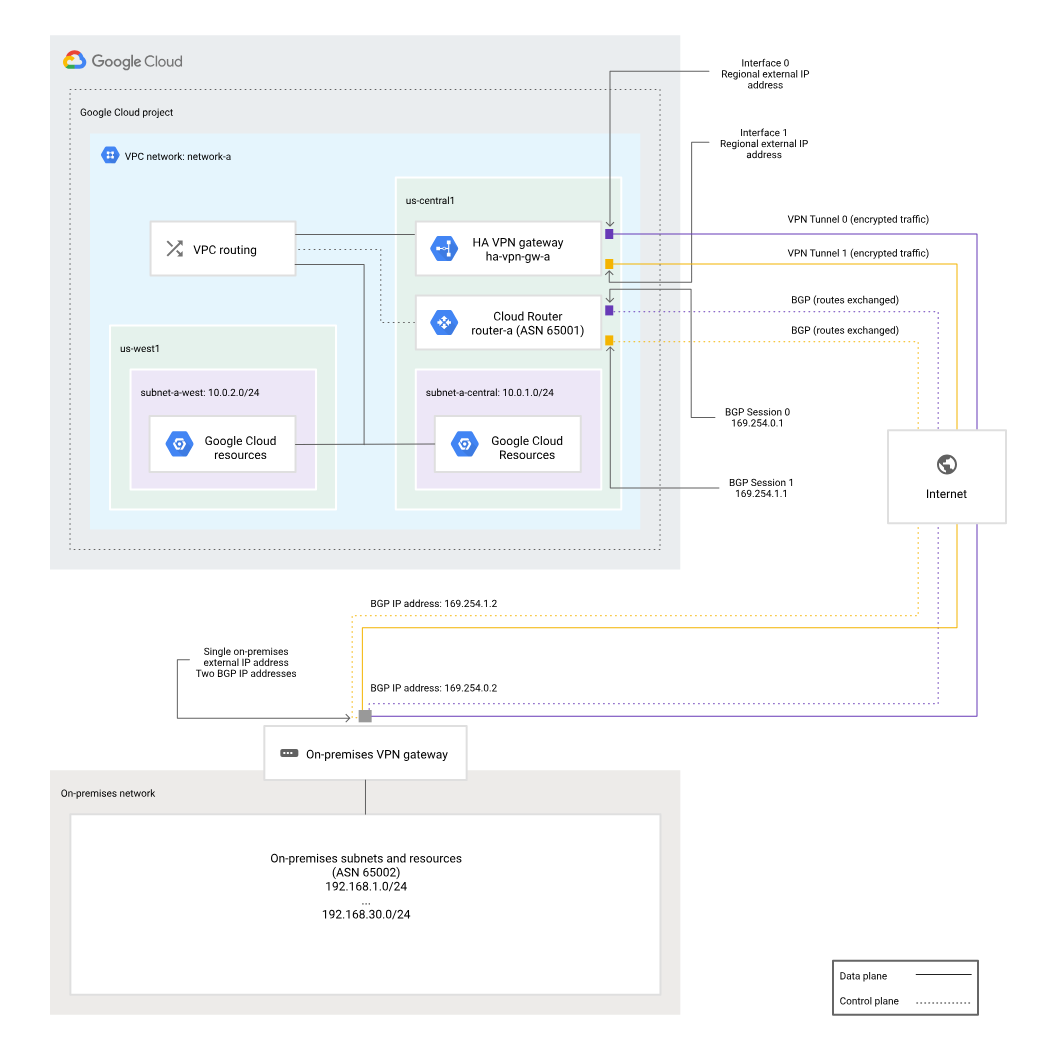
Why We Chose Hub-and-Spoke
I sketched out a rough design on the Miro board (whiteboards are great, but remote teams call for digital scribbles):
Me:
“Alright, what if we use a hub-and-spoke setup? Basically — one central VPC for all the shared stuff. Think of it like your network’s train station. It routes traffic but doesn’t do any heavy lifting itself.”
Here’s the core idea I pitched:
- Hub = `vpc-hub
Handles VPN, Cloud Router (for BGP), DNS, etc. - Spokes = dev/prod/staging shared VPCs
These are where actual workloads run.
Walid:
“So the hub is just pipes and wiring. No apps, no GKE, nothing like that?”
Me:
“Exactly. It’s pure transit. All app stuff lives in the spokes.”
What About Regions?
Me:
“Let’s talk location. Where are your users?”
Yasmine:
“Mostly France and Germany. Like, 80%.”
Easy choice there.
Me:
“Alright, let’s set Paris (`europe-west 9) as your primary region. Maybe Frankfurt (`europe-west3) for backup later. Both are in the EU, which keeps you in good shape for GDPR.”
Nour (Security):
“Yeah, that’s a hard requirement — data has to stay in the EU.”
Me:
“Got it. We’ll lock that in with org policies. That way, nobody ends up launching a VM in Taiwan by accident.”
DNS & Routing — Keep It Simple
Rami (Data):
“Can we make DNS centralized? Or do we have to manage it per VPC?”
Me:
“No need to overcomplicate it. Cloud DNS goes in the hub, we set up private zones, and just peer them to the spoke VPCs. For on-prem resolution, we’ll set up DNS forwarding. Clean and fast.”
Walid:
“Any downside?”
Me:
“Only if your on-prem DNS is flaky. But if it's solid, this setup just works.”
| Topic | Decision | Notes |
|---|---|---|
| Connectivity to GCP | HA VPN | Initial setup from Tunis datacenter to GCP. Interconnect may be considered in future. |
| Network Topology | Hub-and-Spoke | Central hub VPC for VPN, routing, DNS. Spoke shared VPCs for workloads (dev, prod, staging). |
| Hub Role | Transit-only | No workloads or services run in the hub; used only for routing and shared infra. |
| Region Selection | europe-west3 (Frankfurt) | Main traffic is from France and Germany. Future expansion might include europe-west1 (Belgium). |
| DNS Setup | Centralized Cloud DNS in Hub | Private zones with DNS peering to spoke VPCs. DNS forwarding set up for on-prem connectivity. |
| Org Policy: Resource Location | EU Only | To meet GDPR and enterprise compliance. Enforced at org level. |
Need to decide network topology for your organization ? , check this :
Wrap-Up
This was one of those discussions where things clicked. We didn’t try to boil the ocean — just kept it pragmatic. VPN for now. Frankfurt as the anchor region. A clean network layout that scales. No heroics. Just what they need to move forward with confidence.
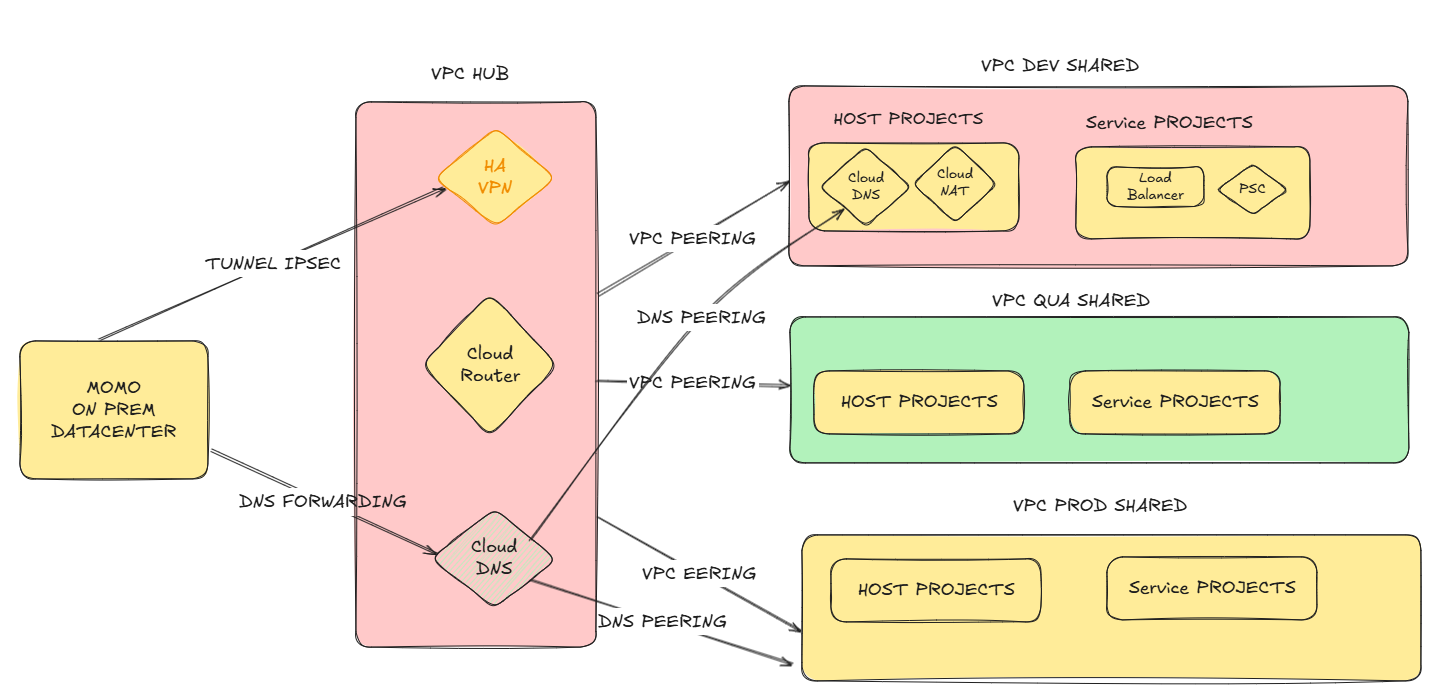
Workshop 3 : Security
Nour was all in on security.
We covered:
- Org Policies to block risky defaults (no public IPs, enforce region restrictions)
- CMEK for sensitive data
- VPC Service Controls around BigQuery, Cloud Storage
- Cloud Armor on edge
- Security Command Center Premium for visibility
They’re gearing up for enterprise clients, so we wanted this part rock-solid.
In the first couple of workshops, we built the skeleton for Momo AI's new cloud home—we sorted out who could get in the door (Identity), drew the map (Folders), and laid the plumbing (Networking).
But after that, you get to the hard part. The part that keeps CTOs up at night.
- How do you know what’s actually happening inside this massive system?
- How do you spot trouble before a customer does?
- And maybe most importantly, how do you prevent a celebratory funding round from being immediately eaten by a surprise cloud bill?
This was the agenda for workshop three. The air in our virtual room was a mix of anticipation and a little bit of dread. It was time to build a nervous system for their cloud.

Workshop 4: Logging & Monitoring : PART 1 Logging
Me : "Next up," I said
Me : "let's talk about logs. Right now, your application logs are basically being written into a diary that immediately gets thrown into a fire."
We had our central-log-project, but it was just an empty box. We had to decide what to put in it.
Me : "Think of it like this," I offered. "We're going to build two kinds of libraries for your logs. First is the front-of-house, searchable library. This is for your critical Audit Logs—the 'who did what, where, and when' that Nour needs for compliance. We'll create a sink that grabs every single one of these logs from across the entire organization and routes them into BigQuery. They'll be instantly queryable and kept for the long haul. This is non-negotiable."
Rami (their head of data, jumped in, rightly concerned.) : "But if we send all our logs to BigQuery, won't that cost a fortune? Our apps can be really chatty in dev."
Me : "Fantastic question. That's why we have the second library," I said.
Me : "Think of it as the cheap, long-term archive. The janitor's closet in the back. For all those verbose debug logs from dev, we'll create a rule that does two things: it sends them straight to a super-cheap Cloud Storage bucket for archival and it tells Cloud Logging to not even bother ingesting them. You save a ton on cost, but if you ever need to dig someone's debug logs out from last Tuesday, you still can. It's the best of both worlds."
The penny dropped. We weren't just collecting logs; we were classifying them based on their value.
And for Nour’s ever-present GDPR concern?
Me : "Easy," I assured her. "The central logging project and all its storage will be locked to the EU. We'll use an Org Policy to make it impossible to store logs anywhere else by accident. That's a hard line in the sand."
Workshop 4: Logging & Monitoring : PART 2 Monitoring
Me:"Okay,"
I started, pulling up our resource hierarchy diagram on the screen.
Me: "Right now, you're flying blind. Let's change that."
I pointed to the two projects we'd created: monitoring-prod and monitoring-nonprod.
Me: "We have actually already made the right choice here. Instead of one giant, messy monitoring setup for everyone, you've got two. This is perfect."
I explained that monitoring-prod would become the command center for everything that touches a real user.
It would have a "single pane of glass" that looked into the production health of the ML platform, the frontend apps—everything. The monitoring-nonprod project would do the same for all the dev and staging environments.
Walid, their sharp infra lead, caught on fast :
Walid: "So, my platform team can live in monitoring-prod and see the whole picture, but the frontend devs can just look at their own project's dashboard if that's all they care about?"Me : "You got it," I said.
Me: "They get a focused view, you get the whole view. Clean separation of concerns."
But this is where the conversation got interesting. A dashboard is passive; it’s what you do with the data that matters.
Me : "Alerts are where the real value is," I said. "But we've all been burned by alert fatigue—a thousand emails you just learn to ignore."
Nour (Security lead): "Tell me about it. A real security event can't get lost in that noise. It needs to be a siren, not a whisper."
Me : "Exactly," I replied. "So we don't just create 'alerts.' We create intelligent routes. A potential security breach from Security Command Center? That triggers a high-priority page to the on-call security person. The dev team's monthly budget is about to be blown? That posts a friendly, but firm, warning in their team's Slack channel. We send the right signal to the right person at the right time." You could almost feel the collective sigh of relief. This wasn't about more noise; it was about clarity.
Workshop 5 : Billing
This was the part of the conversation where Yasmine, the CTO, really tuned in.
Yasmine: "Please," she said, "tell me we can move past 'gut-feel' budgeting. I need to know where the money is going without having to ask five different people."
Me : "That's exactly what this is for,"
I smiled, pointing to the cost-control project on our diagram.
Me : "First, we flip a switch to export all your detailed billing data into BigQuery. That gives us the raw data. But data without context is just numbers. The magic ingredient is labels."
We solidified a simple, non-negotiable rule that would be enforced by policy: no resource gets created without being tagged. At a minimum, it needs to know its team, its env (prod/dev), and its app.
Me : "Once you do that," I explained, "you can ask BigQuery questions in plain English. 'Show me what the ML team spent on production compute last month.' 'Graph the daily storage cost for the data platform.' You’re not just looking at a bill anymore; you're looking at a business intelligence report for your cloud spend."
We decided to build them a few starter dashboards in Looker Studio—a high-level one for Yasmine, and more granular ones for team leads so they could manage their own budgets. We were giving them financial guardrails.
By the end of the session, we didn't just have ideas; we had a blueprint. The action items were clear and destined to become Terraform code:
- Define the monitoring scopes to give the platform team their command center.
- Build the logging sinks to create our compliant, cost-effective log library.
- Turn on the billing export and lock in the label policies.
Workshop 6 : IaC and GitLab
One of the biggest scars from Momo's early, scrappy days was how things got built. A VM here, a firewall rule there—all done by hand in the Google Cloud console. It's the kind of "ClickOps" chaos that works for a week, but leaves you with a technical debt that accrues interest at a terrifying rate.
Me : "We need to start treating your infrastructure like you treat your application code." It's a simple idea, but it’s a profound culture shift.
The best part? They were already using GitLab . They had the right engine; we just needed to teach it to drive their infrastructure safely.
We agreed on a new golden rule: no human manually changes production infrastructure. Ever.
I walked them through the story of a single, safe change: a developer writes a few lines of Terraform code, opens a Merge Request, it gets reviewed by peers, and an automated pipeline runs a terraform plan to show everyone exactly what's about to happen.
But then I paused. I looked directly at Nour, their security lead.
Me : "There's a critical question here," I said. "How does GitLab get the permission to run terraform apply against your Google Cloud projects?"This is the moment where many companies take a dangerous shortcut. They generate a static service account key—basically, a password that never expires—and paste it into a GitLab CI/CD variable.
Me : "That key," I explained, "is a massive liability. If it ever leaks, and these things have a habit of leaking, it's a skeleton key to your kingdom."
Nour: "No. We are not doing that. Absolutely not."
Me : "I'm glad you said that," I smiled. "Because we're not. We're going to do this the right way, using a keyless and much more secure approach called Workload Identity Federation."
I explained it with an analogy.
Me : "Think of it like this: instead of giving GitLab its own permanent key, we're going to teach Google Cloud to trust GitLab directly. Every time a pipeline runs, GitLab generates a special, short-lived token—like a temporary ID card. It presents this ID to Google Cloud. Google looks at it and says, 'Ah, I see this ID is from GitLab, which I've been configured to trust. I'll grant you temporary, limited access. Come on in.'" "No static keys. No long-lived credentials stored in GitLab. Just a secure, temporary handshake based on trust."
Me : "But just getting in the door isn't enough," I continued. "We also have to ensure the pipeline can only do what it's supposed to do. This is where Service Account Impersonation comes in."
Me : "Once GitLab has authenticated, it doesn't get free rein. Instead, it's given the temporary ability to impersonate a very specific, low-privilege service account. So, the pipeline for the ml-ai-dev project can only impersonate a service account that can touch resources in that one project. It literally doesn't have the permission to even see the production database, let alone delete it."You could see the relief wash over Nour's face.
We weren't just building an automated pipeline; we were building a secure one. The audit trail wouldn't just show that GitLab made a change; it would show it did so by securely impersonating a specific, permission-scoped service account, all without a single static key anywhere in the system.
Me : "Now that we've got the security model locked down," I continued, "let's talk about organizing your Terraform code within GitLab itself. For Momo's scale and need for governance, I strongly recommend we establish two distinct GitLab repositories for your infrastructure."
I elaborated :
Me : "First, we'll have a 'GCP Landing Zone' GitLab repository. This repo will house the Terraform code for your foundational GCP infrastructure: think project creation, organization-level policies, core networking components like Shared VPCs, foundational IAM roles, and centralized logging configurations. These are the 'modules' that other teams will consume."
"Then, for each of your application teams – like the ml-ai-dev team – they will have their own separate GitLab repository for their application-specific infrastructure. This is where they'll define their Cloud Run services, specific firewall rules for their microservices, Pub/Sub topics, or specialized AI Platform resources. Crucially, these application repositories will consume and utilize the modules defined in the 'GCP Landing Zone' repo."Walid, their infra lead, chimed in : "So, if the ml-ai-dev team needs a new GCP project, instead of writing all the project creation logic themselves, they'd just call a 'create project' module from the Landing Zone repo?"Me : "Exactly!" I confirmed. "It ensures consistency, enforces best practices set at the organizational level, and significantly speeds up application team onboarding. The Landing Zone team manages the 'how to create a project properly' module, and the application teams just declare 'I need a project' and consume it. It's true infrastructure abstraction."
Me : "This separation of concerns," I explained, "allows the Landing Zone team to focus on foundational security and governance, while empowering application teams to rapidly provision and manage their own resources within predefined guardrails. It's how we achieve both agility and control, especially as you scale to millions of users."
What’s Next?
I’m writing up the full architecture doc now — everything we covered, plus diagrams and example policies.
Then, we’ll roll out a first workload into the new Landing Zone — just one app, so we can validate the blueprint end-to-end before scaling.
Stay Tuned to get more infos 😊
